Hardware Support (CPU/GPU)
Using a CPU
|
●
|
Deep learning algorithms perform a lot of computations and can be very slow to train on a CPU. |
|
●
|
The deep learning tools support CPU processing for both 32-bit and 64-bit applications. |
|
□
|
The memory of a 32-bit application is limited to 2 GB and this can slow the training or the classification of large images. |
|
□
|
The 64-bit version better supports the SIMD instructions of modern CPUs and is usually faster than the 32-bit version. |
Using an NVIDIA CUDA® GPU
Using a recent NVIDIA GPU greatly accelerates the processing speeds. Refer to the benchmarks for each tool type to compare the GPU and CPU speeds.
|
1.
|
To use an NVIDIA GPU with the deep learning tools, install the following NVIDIA libraries on your computer: |
|
2.
|
According to the installation location: |
|
□
|
If you install the NVIDIA CUDA® Toolkit in its default location (C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1), a deep learning tool automatically finds what it needs. |
|
□
|
Otherwise, copy the DLLs cusolver64_11.dll, curand64_10.dll, cufft64_10.dll and cublas64_11.dll in the Open eVision DLL folder (its default location is C:\Program Files (x86)\Euresys\Open eVision X.X\Bin64\). |
|
3.
|
Install the NVIDIA CUDA ® Deep Neural Network library (cuDNN) that comes as a zip archive: |
|
c.
|
If the NVIDIA CUDA® Toolkit is not installed in its default location, copy all the DLL files cudnn*8.dll in the Open eVision DLL folder (its default location is C:\Program Files (x86)\Euresys\Open eVision X.X\Bin64\). |
|
●
|
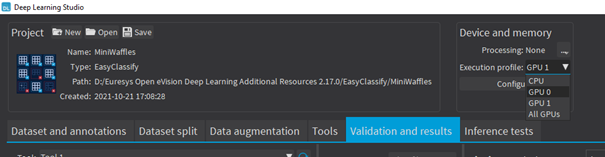
In Deep Learning Studio, to choose the processing devices, select an execution profile. |
|
●
|
You can configure these execution profiles to match your needs. |
|
●
|
GPU processing is not possible with 32-bit applications. |
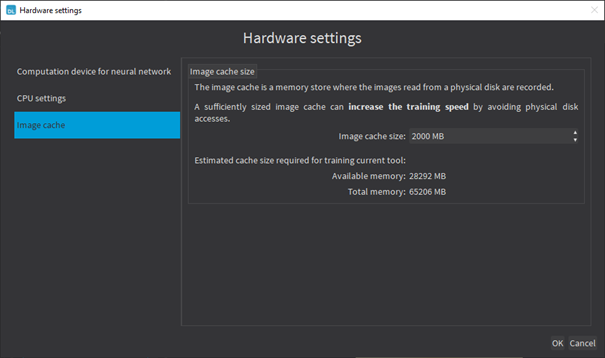
Image cache
The image cache is the part of the memory reserved for storing images during training.
|
●
|
The default size is 1 GB. |
|
●
|
With large dataset, increasing the image cache size may improve the training speed. |
To specify the cache size in bytes:
|
●
|
In Deep Learning Studio, click on the Configure button below the Execution profile control and select Image cache in the menu. |
Multicore processing
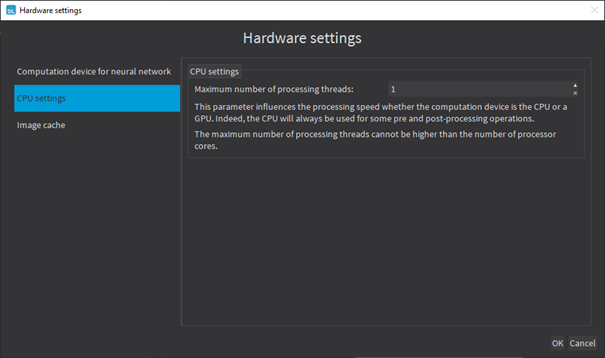
The deep learning tools support multicore processing (see Multicore Processing):
|
●
|
In Deep Learning Studio, click on the Configure button below the Execution profile control and select CPU Settings in the menu. |