EasyClassify - Classifying Images
EasyClassify is the deep learning classification library of Open eVision (EClassifier class).
Deep Learning Studio
To create a classification tool in Deep Learning Studio:
|
1.
|
Start Deep Learning Studio. |
|
2.
|
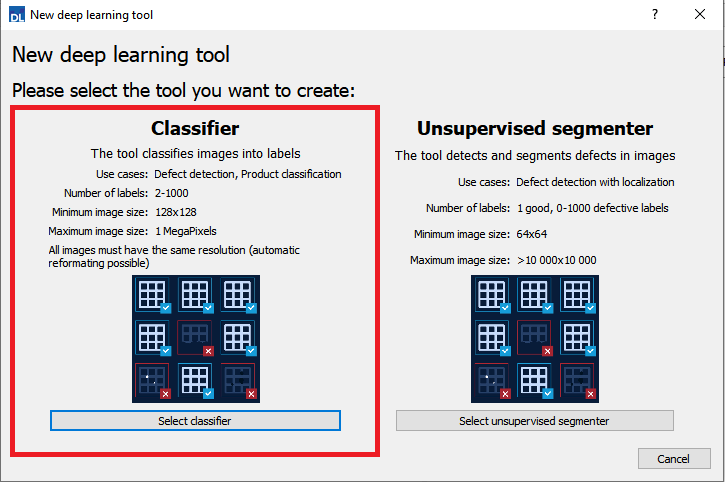
Select Classifier in the New deep learning tool dialog.
|
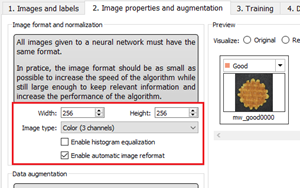
Input image format and normalization
|
●
|
The input image format must have the width, height and number of channels corresponding to the input of the neural network. |
|
●
|
By default, a classifier uses the image format of the first image inserted in the training dataset: |
|
□
|
All other images are automatically reformatted (anisotropic rescaling and conversion between color and grayscale). |
|
●
|
In Deep Learning Studio, you can set the input image format in the Image properties and augmentation tab. |
|
●
|
In the API, you can also set manually the input image format with the methods SetWidth, SetHeight and SetChannels (1 channel for grayscale images and 3 channels for color images). |
|
●
|
The input image format must have a resolution between 128 x 128 and 1024 x 1024.
For the best processing speed, use the lowest resolution at which your "objects of interest" are still recognizable. |
|
□
|
If your original images are smaller than the minimum resolution, upscale them to a resolution higher or equal to 128 x 128. |
|
□
|
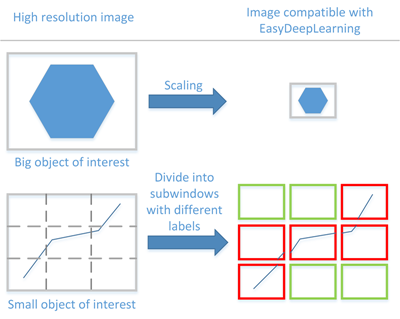
If your original images are larger than the maximum resolution, lower the resolution:
- If the "objects of interest" are still recognizable, explicitly set the input image format of the classifier to this lower resolution.
- If the "objects of interest" are not recognizable, divide your original images into sub-windows and use these sub-windows to train the classifier and make prediction. This presents the additional advantage of localizing the "object of interest" inside the original image. |
Histogram equalization
The classifier can also apply an histogram equalization to every input image:
|
□
|
In Deep Learning Studio, activate it in the image format controls in the Image properties and augmentation tab. |
Training the classifier
In the API, to train a classifier, call the method EClassifier::Train(trainingDataset, validationDataset, numberOfIterations).
|
□
|
An iteration corresponds to going through all the images in the training dataset once. |
|
□
|
The training process requires a large number of iterations to obtain good results. |
|
□
|
The default number of iterations is 50. |
|
□
|
The larger the number of iterations, the longer the training is and the better the results you obtain. |
Calling the EClassifier::Train() method several times with the same training and validation dataset is equivalent to calling EClassifier::Train() once but with a larger number of iterations. The total number of iterations used to train the classifier is accessible through EClassifier::GetNumTrainedIterations().
|
●
|
The training process is asynchronous: |
The batch size corresponds to the number of images that are processed together.
|
□
|
The training is influenced by the batch size. |
|
□
|
A large batch size increases the processing speed of a single iteration on a GPU but requires more memory. |
|
□
|
The training process is not able to learn a good model with too small batch sizes. |
|
□
|
By default, the batch size is determined automatically during training to optimize the training speed with respect to the available memory. |
- Use EDeepLearningTool::SetOptimizeBatchSize(false) to disable this behavior.
- Use EDeepLearningTool::SetBatchSize to change the size of your batch.
|
□
|
It is common to choose powers of 2 as batch size for performance reasons. |
Validating the results
In Deep Learning Studio:
|
●
|
The metrics are always computed without applying data augmentation on the images. |
|
●
|
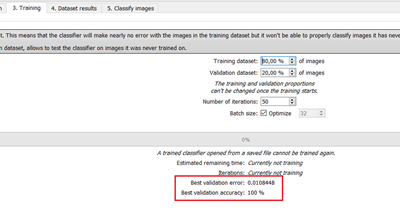
In the Training tab, the metrics Best validation error and Best validation accuracy are computed during the training using the label weights. |
|
●
|
In the Dataset results tab, there are 3 metrics displayed: |
|
□
|
The weighted error and the weighted accuracy (normalized with respect to the label weights instead of being dependent of the number of images for each label). |
|
□
|
The dataset accuracy (it does not use the label weights). |
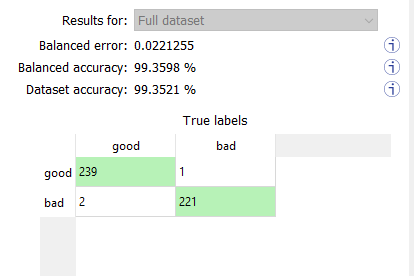
If your dataset has a very different number of images for each of the labels, it is called unbalanced. In this case, the dataset accuracy is biased towards the labels containing the most images (the dataset accuracy mainly reflects the accuracy of these labels).
|
●
|
In the Dataset results tab, the confusion matrix shows the number of images according to their true labels and their label predicted by the classifier. |
|
□
|
The diagonal elements of the matrix shown in green are the correctly classified images. |
|
□
|
All the other elements of the matrix are badly classified images. |
|
□
|
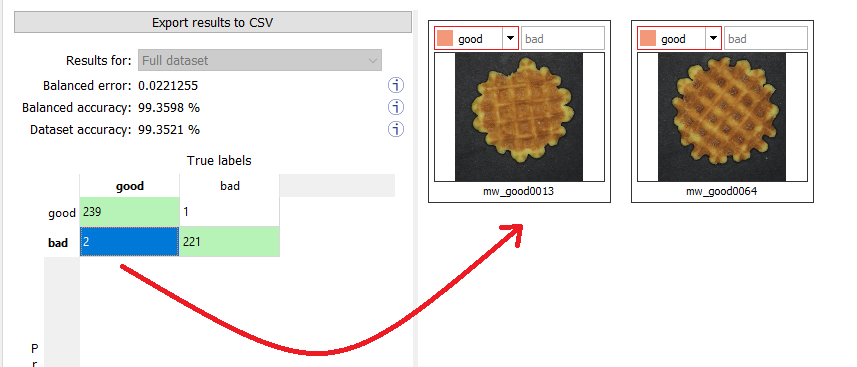
Select one or more elements of the matrix to show the corresponding images. |
In the API:
|
●
|
After the completion of each iteration, EasyClassify automatically computes several performance metrics about the training and validation dataset: |
|
□
|
After the training, the classifier is back in the state corresponding to this best iteration. |
|
●
|
The metrics are represented by an EClassificationMetrics object that contains the following performance metrics: |
|
□
|
The classification error (EClassificationMetrics::GetError()), also called the cross-entropy loss: the quantity that is minimized during the training. It is computed from the probabilities computed by the classifier. |
- The error for a single image is the negative of the logarithm of the probability corresponding to the true label of the image. So, if this probability is low, the error for the image is high.
- The error of the dataset is the average of the errors of each image in the dataset.
Classifying new images
|
●
|
In Deep Learning Studio, open Classify images tab to: |
|
□
|
Display detailed results for each image of the main dataset. |
|
●
|
You can also do batch classification or directly classify a vector of Open eVision images: |
|
□
|
Images are processed together in groups determined by the batch size. |
|
□
|
On a GPU, it is usually much faster to classify a group of images than a single image. |
|
□
|
On a CPU, implement a multithread approach to accelerate the classification. In that case, each thread must have its own instance of EClassifier (see code snippets). |
The batch classification has a tradeoff between the throughput (the number of images classified per second) and the latency (the time needed to obtain the result of an image): on a GPU, the higher the batch size, the higher the throughput and the latency. So, use batch classification to improve the classification speed at the cost of a longer time before obtaining the classification result of an image.
|
●
|
Use EClassifier::GetHeatmap(img, label) to obtain an heat map highlighting the pixels that contribute the most to a label. In some cases, this heat map can provide a rough localization of the object corresponding to the label. |
Memory requirements
|
●
|
In addition to the properties of the classifier object and the weights of the neural network, an EClassifier object dynamically allocates memory for intermediate results during the training and the classification of new images. |
|
●
|
The size of the intermediate results depends on the width (W), height (H), batch size (B), and whether the operations are performed on a GPU or a CPU. |
|
●
|
For training, these intermediate results need about the following amount of memory: |
TrainingMemoryCPU = 0.000453 × W × H × B – 292 (MB)
TrainingMemoryGPU = 0.000440 × W × H × B + 25 (MB)
|
●
|
For classification, these intermediate results need up to the following memory: |
ClassificationMemoryCPU = 0.000232 × W × H × B – 97 (MB)
ClassificationMemoryGPU = 0.000226 × W × H × B + 13 (MB)
|
●
|
For example, training a classifier or making classifications with 256 x 256 images and a batch size of 32 on a GPU will take around respectively 950 MB or 500 MB. |
Since large memory allocations take a lot of time, a classification does not released this memory and the next classifications can reuse it as long as the width, height, batch size and computation device remain the same. As such, the first classification is always be slower due to the memory allocations.
