EasyClassify - Classifying Images
EasyClassify is the deep learning classification library of Open eVision (EClassifier class).
Deep Learning Studio
To create a classification tool in Deep Learning Studio:
|
1.
|
Start Deep Learning Studio. |
|
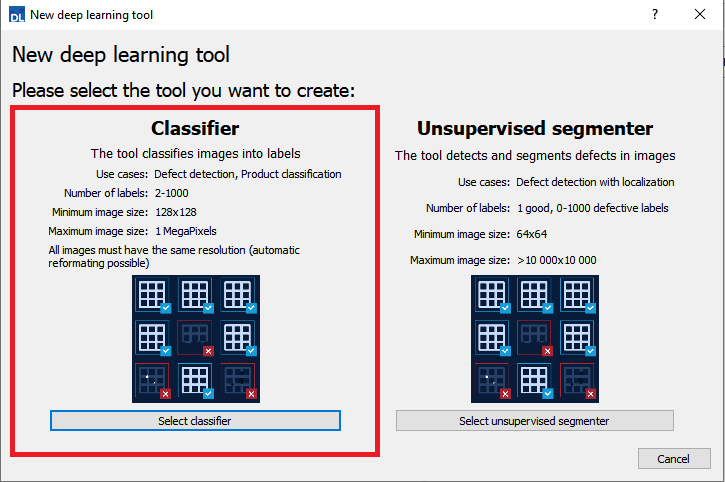
2.
|
Select Classifier in the New deep learning tool dialog. |
入力画像フォーマットと正規化
|
●
|
入力画像フォーマットはニューラルネットワークに対応する幅、高さ、およびチャンネル数を有している必要があります。 |
|
●
|
デフォルトでは、クラシファイアはトレーニングデータセットに挿入された最初の画像の画像フォーマットを使用します。 |
|
□
|
他のすべてのイメージは自動的に再フォーマットされます(異方性のリスケーリングとカラーとグレースケール間の変換)。 |
|
●
|
In Deep Learning Studio, you can set the input image format in the Image properties and augmentation tab. |

|
●
|
In the API, you can also set manually the input image format with the methods SetWidth, SetHeight and SetChannels (1 channel for grayscale images and 3 channels for color images). |
|
●
|
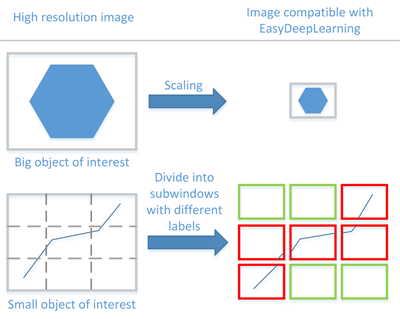
入力画像フォーマットの解像度は128 x 128 - 1024 x 1024の間である必要があります。
最高処理速度を得るには、「関心オブジェクト」が認識可能な最低限の解像度を使用します。 |
|
□
|
オリジナルの画像が最低解像度よりも小さい場合、128 x 128以上の解像度にアップスケールします。 |
|
□
|
オリジナルの画像が最大解像度よりも大きい場合、解像度を下げます:
- 「関心オブジェクト」がまだ認識できる場合は、明示的に分類子の入力画像フォーマットをこの低い解像度に設定します。
- 「関心オブジェクト」が認識できない場合は、オリジナルの画像をサブウィンドウに分けて、これらのサブウィンドウを使用して分類子が予測する訓練をします。これには、オリジナルの画像の中で「関心オブジェクト」をローカライズするというメリットもあります。 |
ヒストグラムの平滑化
The classifier can also apply an histogram equalization to every input image:
|
□
|
In Deep Learning Studio, activate it in the image format controls in the Image properties and augmentation tab. |
分類子のトレーニング
バッチのサイズは、一緒に処理される画像の数に対応します。
|
□
|
トレーニングはバッチのサイズの影響を受けます。 |
|
□
|
大きなバッチのサイズは、GPU上の1つのループの処理速度を向上させますが、より多くのメモリを必要とします。 |
|
□
|
トレーニングプロセスでは、小さすぎるバッチのサイズでは良いモデルを学習できません。 |
|
□
|
デフォルトでは、バッチサイズは利用可能なメモリの観点からトレーニングのスピードを最適化するためにトレーニング中に自動的に決定されます。 |
- Use EDeepLearningTool::SetOptimizeBatchSize(false) to disable this behavior.
- Use EDeepLearningTool::SetBatchSize to change the size of your batch.
|
□
|
パフォーマンス上の理由から、バッチのサイズとして2のべき乗を選択するのが一般的です。 |
結果の検証
Deep Learning Studio:
|
●
|
The metrics are always computed without applying data augmentation on the images. |
|
●
|
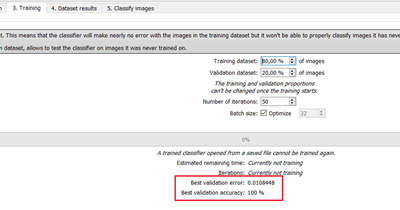
In the Training tab, the metrics Best validation error and Best validation accuracy are computed during the training using the label weights. |
|
●
|
In the Dataset results tab, there are 3 metrics displayed: |
|
□
|
The weighted error and the weighted accuracy (normalized with respect to the label weights instead of being dependent of the number of images for each label). |
|
□
|
The dataset accuracy (it does not use the label weights). |
If your dataset has a very different number of images for each of the labels, it is called unbalanced. In this case, the dataset accuracy is biased towards the labels containing the most images (the dataset accuracy mainly reflects the accuracy of these labels).
|
●
|
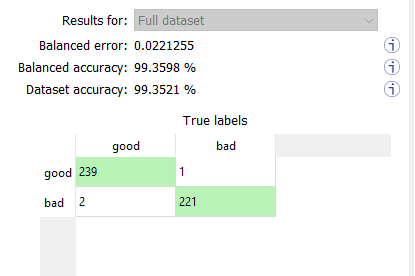
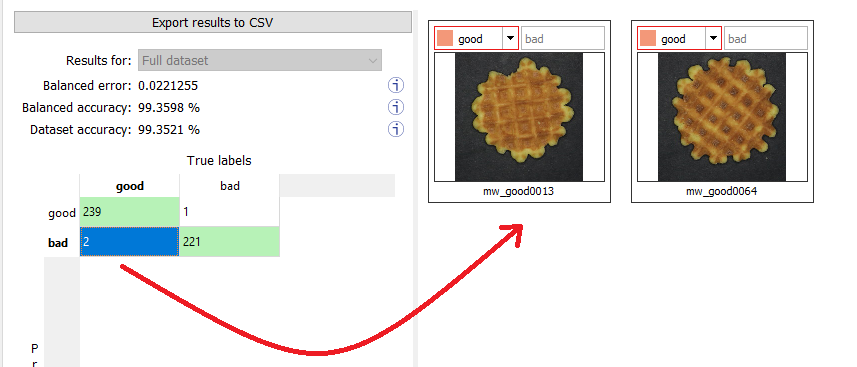
In the Dataset results tab, the confusion matrix shows the number of images according to their true labels and their label predicted by the classifier. |
|
□
|
The diagonal elements of the matrix shown in green are the correctly classified images. |
|
□
|
All the other elements of the matrix are badly classified images. |
|
□
|
Select one or more elements of the matrix to show the corresponding images. |
In the API:
|
●
|
After the completion of each iteration, EasyClassify automatically computes several performance metrics about the training and validation dataset: |
|
□
|
トレーニングの後、クラシファイアはこの最良のループに対応する状態に戻ります。 |
|
□
|
The classification error (EClassificationMetrics::GetError()), also called the cross-entropy loss: the quantity that is minimized during the training. It is computed from the probabilities computed by the classifier. |
- The error for a single image is the negative of the logarithm of the probability corresponding to the true label of the image. So, if this probability is low, the error for the image is high.
- The error of the dataset is the average of the errors of each image in the dataset.
新しい画像の分類
|
●
|
In Deep Learning Studio, open Classify images tab to: |
|
□
|
Display detailed results for each image of the main dataset. |
|
●
|
You can also do batch classification or directly classify a vector of Open eVision images: |
|
□
|
画像は、バッチのサイズによって決定されるグループで一緒に処理されます。 |
|
□
|
通常、画像のグループを1つの画像を分類するよりはるかに高速です。 |
The batch classification has a tradeoff between the throughput (the number of images classified per second) and the latency (the time needed to obtain the result of an image): on a GPU, the higher the batch size, the higher the throughput and the latency. So, use batch classification to improve the classification speed at the cost of a longer time before obtaining the classification result of an image.
メモリ要件
|
●
|
分類子オブジェクトのプロパティとニューラルネットワークの重みに加え、EClassifierオブジェクトはトレーニングや新しい画像の分類分け中に途中結果用のメモリを動的に割り当てます。 |
|
●
|
途中結果のサイズは幅(W)、高さ(H)、バッチサイズ(B)、および操作がGPUとCPUのどちらで実行されたかに依存します。 |
|
●
|
トレーニングでは、これらの途中結果は以下程度のメモリを必要とします。 |
TrainingMemoryCPU = 0.000453 × W × H × B – 292 (MB)
TrainingMemoryGPU = 0.000440 × W × H × B + 25 (MB)
|
●
|
分類分けでは、これらの途中結果は最大で以下のメモリを必要とします。 |
ClassificationMemoryCPU = 0.000232 × W × H × B – 97 (MB)
ClassificationMemoryGPU = 0.000226 × W × H × B + 13 (MB)
|
●
|
例えば、256 x 256 画像での分類子のトレーニングまたは分類分けで、GPU上でバッチサイズが32であった場合、950MBまたは500MBほどのメモリが必要になります。 |
大きなメモリ割り当てには時間がかかりますので、分類分け中にこのメモリは解放されず、幅、高さ、バッチサイズ、および計算装置が同じである限り次の分類分けで再利用されます。そのため、メモリ割り当ての関係で最初の分類分けが常に遅くなります。
