
EasyOCR2——改进的文本读取
EasyOCR2 是一种光学识别库,用于读取标签或部件上打印的短文本,如序列号、到期日期或批号。
它使用创新的分割方法来检测图像中的斑点,然后根据用户定义的拓扑(文本中的行数,文字和字符)将文本框放置在检测到的斑点上。 这些方法支持文本旋转高达 360 度,可以处理不均匀的照明、纹理背景以及点印或碎片字符。
可以为文本中的每个字符指定字符类型(字母/数字/符号),从而提高识别率和速度。 用于进行识别的字符数据库可以从样本图像中学习,也可以从 TrueType 字体(.ttf)文件读取。
EasyOCR2的文本识别有四个阶段:

输入图像(左)和适合的文本框(右)


图像分割(左)和识别(右)
EasyOCR2在处理如下内容时会比EasyOCR提供更好的结果:
| □ | 未知文字旋转 |
| □ | 虚线或碎片字符 |
| □ | 不均匀的照明或纹理背景 |
| ● | 当TrueType字体文件与可读取的文本相匹配时,EasyOCR2允许用户直接使用这些字体文件进行识别,而EasyOCR则不允许。 |
| ● | 当上述都不适用于应用程序时,由于其卓越的计算速度,用户可能更喜欢使用EasyOCR而非EasyOCR2。 |
EasyOCR2以如下方式在图像中查找字符:
| 1. | EasyOCR2分割图像,找到代表字符(部分)的斑点。 |
| 2. | 过大或过小的不能被视为字符部分的斑点会被过滤掉。 |
| 3. | 根据给定的拓扑和检测方法,EasyOCR2将字符框匹配检测到的斑点。 |
拓扑描述了图像中文本的结构,定义行数、每行字数和每字字符数。
| 4. | EasyOCR2从图像中提取每个字符框内的像素。 |
所得到的字符图像可用于学习或识别字符。
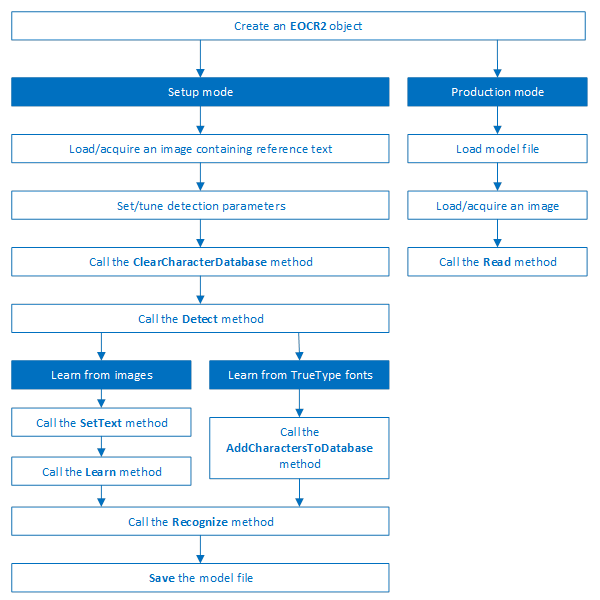
图像中的工作流检测文本可以如下所示:
| a. | 设置所需的检测参数。 |
| b. | 或者,调用Load以读取包含来自磁盘的检测参数的预制模型(.o2m)文件。 |
| c. | 调用检测从图像中提取文本。 |
Detect方法将返回一个EOCR2Text结构,其中包含每个字符的文本框和位图图像,分层存储在EOCR2Line -> EOCR2Word -> EOCR2Char 结构中。
请参见代码片段示例: Detecting Characters

使用detectionMethod ‘EOCR2DetectionMethod_FixedWidth’检测方法处理的固定宽度字体的示例

使用detectionMethod ‘EOCR2DetectionMethod_Proportional’检测方法处理的比例字体的示例

当NumDetectionPasses = 1 时,该图像的textAngle估计略有偏离

当NumDetectionPasses = 2 时,textAngle的估计更好

对于这个虚线文本,将“ CharsMaxFragmentation ”设置为0.1将导致不完整的分割结果

将“CharsMaxFragmentation”设置为0.01可以提供更好的分割结果
必需参数
| □ | 参数Topology告诉框适配方法如何构建适合检测到的斑点的文本框。 使用Regex表达式的修改版本,拓扑确定文本中的行数、每行的单词数和每个字的字符数。 识别参数部分包含了拓扑语法的扩展解释。 |
| □ | 参数CharsWidthRange说明分割和检测方法图像中字符的宽度范围。 |
| □ | 参数CharsHeight说明分割和检测方法图像中字符的高度范围。 |
| □ | 参数TextPolarity告诉分割方法是否应该在深色背景上寻找亮色字符,反之亦然。 |
高级分割参数(可选):
| □ | CharsMaxFragmentation参数说明了分割算法可以被考虑为一个字符(部分)的斑点面积范围。 斑点的最小允许面积由下式给出: |
minArea = CharsMaxFragmentation * CharsHeight * min(CharsWidthRange)
该参数应设置在0和1之间,默认设置为0.1。
| □ | MaxVariation参数确定图像中斑点的稳定程度,以便被认为是可能的字符。 |
具有明确限定边缘的区域通常会被认为是稳定的,而模糊区域则不会。 高设置允许较不稳定的斑点,低设置只允许非常稳定的斑点。
该参数应设置在0和1之间,默认设置为0.25。
| □ | DetectionDelta参数确定用于确定斑点稳定性的灰度值范围。 |
低设置将使算法对噪声更敏感;高设置将使算法对背景对比度较低的斑点敏感。
该参数应设置在1和127之间,默认设置为12。
高级检测参数(可选)
| □ | 参数DetectionMethod选择用于适配的算法。 设置 EOCR2DetectionMethod_FixedWidth (默认)针对具有固定宽度字体(包括虚线文本)的文本进行了优化,设置 EOCR2DetectionMethod_Proportional 针对具有比例字体的文本进行了优化。 |
| □ | TextAngleRange参数说明了框适配方法如何定位图像中的文本。 它将测试以下旋转角度范围: |
min(TextAngleRange) ≤ angle ≤ max(TextAngleRange)
其中根据水平线限定角度。 角度(度/弧度/转数/等级)的单位可以由easy::SetAngleUnit()设置。
该参数的默认设置为[-20, 20]度。
| □ | 参数NumDetectionPasses决定了将文本框适配到检测到的斑点的通道数量。 初始通道将文本框适配到所有检测到的斑点。 随后的通道将仅选择上一次通道的文本框覆盖的那些斑点,并将文本框适合于该斑点子集,从而可能导致更优化的适配。 |
该参数应设置为1或2,默认设置为1。
高级参数,特定于设置EOCR2DetectionMethod_FixedWidth
| □ | RelativeSpacesWidthRange参数告诉框适配方法字之间空格的宽度范围。 它将测试以下范围的空格: |
min(SpacesWidthRange) * charWidth ≤ space ≤ max(SpacesWidthRange) * charWidth
| □ | CharsWidthBias参数将偏向较窄字符框的较宽优化。 |
| □ | CharsSpacingBias参数将偏向到字符之间较小或较大间距的优化。 |
附加说明
| □ | 选择 EOCR2DetectionMethod_FixedWidth 设置时,所有字符框的宽度都相同,并不一定要紧紧围绕字符。 |
| □ | 当选择 EOCR2DetectionMethod_Proportional 设置时,字符框将紧紧围绕在字符周围,如果任何字符超出允许的字符宽度范围,检测将失败。 |
为了识别字符,EasyOCR2需要一个已知参考字符的数据库。 我们可以从图像和/或TrueType系统字体生成该字符数据库。
构建字符数据库的工作流可以如下所示:
| a. | 设置所需的检测参数或调用Load从磁盘读取模型(.o2m)文件。 |
| b. | 或者,调用ClearCharacterDatabase 来清除当前的字符数据库。 |
| c. | 调用检测从图像中提取文本。 |
| d. | 在提取的文本结构中调用SetText,为每个字符设置正确的值。 |
| e. | 调用Learn将检测到的字符及其正确的值添加到当前字符数据库。 |
| f. | 调用SaveCharacterDatabase将当前字符数据库保存到磁盘。 |
| g. | 或者,调用Save将模型文件保存到磁盘,包括检测参数和创建的字符数据库。 |
请参见代码片段示例: Learning Characters
EasyOCR2使用在字符数据库上训练的分类器来识别字符。 对于每个输入字符,分类器将计算所有候选输出的分数,并返回具有最高分数的候选者作为识别结果。 通过Topology参数,可以将有关每个字符的先前信息传递给分类器,减少候选者数量,提高识别率。
用于从图像识别文本的生产工作流程可以如下:
| □ | 调用Load从磁盘读取模型(.o2m)文件。 模型文件包含所有检测参数,以及拓扑和参考字符数据库。 |
| □ | 加载或获取图像。 |
| □ | 调用Read以检测并识别字符。 |
| □ | 或者,调用Detect从图像中提取文本,然后调用Recognize来识别提取的文本。 如果需要,这允许用户在识别之前修改检测到的文本元素。 |
Read和Recognize方法将返回带有识别结果的字符串。 要访问有关结果的更多深入信息,可以调用ReadText。 这将返回包含每个文本框坐标和大小,以及每个字符的位图图像和识别分数列表的EOCR2Text结构。
请参见代码片段示例: Reading Characters
识别参数
Topology参数指定文本的结构(行/字/字符数)以及文本中的字符类型。 识别方法将基于给定的拓扑来限制每个字符的候选数量。
它使用Regex表达式的修改版本,其中:
| □ | “.” (点)表示任何字符(不包括空格)。 |
| □ | “L”表示字母字符。 |
- “Lu”表示大写字母字符。
- “Ll”表示小写字母字符。
| □ | “N”表示数字。 |
| □ | “P”表示标点符号:! “ # % & ‘ ( ) * , - . / : ; < > ? @ [ \ ] _ { | } ~ |
| □ | “S”表示符号:$ + - < = > | ~ |
| □ | “\n“代表换行。 |
| □ | “”(空格)表示两个单词之间的空格。 |
可以进行组合,例如:[LN]表示字母数字字符。 要指定多个字符,只需在n个字符的末尾添加{n}。 如果字符数量不确定,请指定{n,m}至少为n个字符,最多为m个字符。
拓扑“[LuN]{3,5}PN{4}\n.{5}LL“表示由2行组成的文本:
| □ | 第一行有1个字,由3到5个大写字母数字字符组成,后跟一个标点符号和4位数字。 |
| □ | 第二行有2个字。 第一个字由5个通配符组成,第二个字有2个字母(大写或小写)。 |
拓扑“L{3}P N{6}\nL{3 }P NNPN{4}“表示具有2行的文本:
| □ | 第一行有2个字。 第一个字有3个大写字母,后跟一个标点符号,第二个字有6位数字。 |
| □ | 第二行也有两个字。 第一个字有3个大写字母,后跟一个标点符号。 第二个字有2位数字,后跟一个标点符号和4位数字。 |
拓扑“.{10}\n .{7} \n .{5} .{5} \n.{5}.{7}“表示4行的文本:
| □ | 第一行包含一个10(ASCII)个字符的单字 |
| □ | 第二行包含一个7个字符的单字 |
| □ | 第三行包含两个字,每个字有5个字符。 |
| □ | 第四行包含两个字,分别有5个和7个字符。 |