
光学文字認識ライブラリEasyOCRは短い文字データ(シリアル番号、部品番号、日付など)を読み取ります。
そのために、きちんと印字されていない文字や破損した文字、繋がった文字、任意のサイズの文字を認識可能なテンプレートマッチングアルゴリズムと、さまざまなフォントファイル(事前定義OCR-A、OCR-Bおよびセミスタンダードフォント、またはその他の学習されたフォント)を使用します。
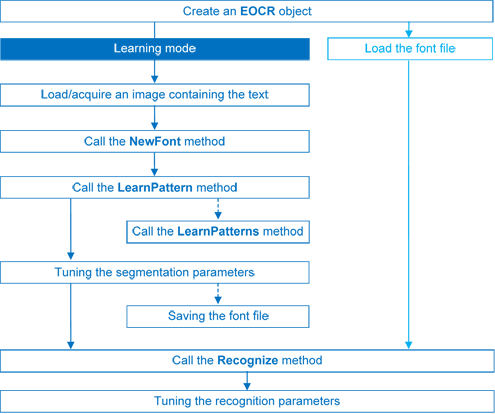
文字認識は次の4つのステップで行われます:
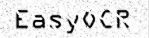
|
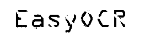
|
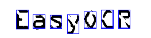
|
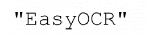
|
| 1. 原画像 | 2. オブジェクトセグメンテーション | 3. 文字分離 | 4. 文字認識 |
必要に応じて、文字を学習してフォントファイルを作成することができます。
文字は一つずつEasyOCRに取り込まれ、分析された後、フォントと呼ばれる文字データベースが構築されます。文字には固有の数字コード(通常はそのASCIIコード)があり、特定の文字クラスに属します(認識プロセスで使用可能)。
フォントファイルは次のようにして作成します:
- NewFontによって現在のフォントを消去します。
- LearnPatternまたはLearnPatternsで原画像からフォントにパターンを追加します。
パターンはFindAllCharsプロセスで割り当てられたインデックス値で並べられます。
フォントに含まれる各パターンは、デフォルトでは幅5ピクセル、高さ9ピクセルの小さいピクセル配列として保存されます。このサイズは学習前にPatternWidthおよびPatternHeightパラメータで変更できます。 - RemovePatternにより不要なパターンを削除します(オプション)。
- Saveでフォントの内容をディスクファイルに書き込みます。その際、次のパラメータ値が書き込まれます:NoiseArea、MaxCharWidth、MaxCharHeight、MinCharWidth、MinCharHeight、CharSpacing、TextColor。
- EasyOCRはブロブを解析して文字とそのバウンディングボックスの位置を特定します。その際、2つのセグメンテーションモードのうちいずれかを使用します:
- オブジェクト保持モード:1つのブロブが1文字に相当します。
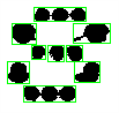
- オブジェクト再貼り付けモード:ブロブがグループ化されてノミナルサイズの文字になります。このモードは文字が破損していたり複数の部分から構成されている場合に便利です。1つのブロブが1つの文字としては大きすぎる場合、CutLargeCharsによって自動的に分割できます。
![]()
ブロブのグループ化による文字の分割
2. フィルタを使って、非常に大きい/小さい不要な形状を取り除きます。
3. EasyOCRは文字画像を処理してバウンディングボックスに合うようにサイズを正規化し、該当する形状を抽出してフォントファイルに保存します。フォントに含まれる各パターンは、PatternWidthおよびPatternHeightで定義されているピクセル配列(デフォルトでは幅5ピクセル、高さ9ピクセル)として保存されます。
セグメンテーションパラメータは学習および認識の間、同じでなければなりません。適切なセグメンテーションにより認識が改善します。
- Thresholdパラメータは背景から文字列を分離する際に役立ちます。
この値が大きすぎると白地にある黒の文字が太くなって各要素が結合するおそれがあり、小さすぎると部分的に見えなくなるおそれがあります。
照明条件が頻繁に変化する状況では、自動閾値化を選択することをお勧めします。



閾値が高すぎ(左)、閾値の調整(中央)、閾値が低すぎ(右)
- NoiseArea:この値よりも小さいブロブ面積は除外されます。文字に含まれる小さい部分が除外されていないか確認してください(「i」文字の上の点など)。
- MaxCharWidth、MaxCharHeight:最大文字サイズ。この寸法の長方形内に入らないブロブは除外されるか、縦方向の切断線によって複数の部分に分割されます。複数のブロブがこの寸法の長方形内に入る場合、まとめてグループ化されます。
- MinCharWidth、MinCharHeight:最小文字サイズ。この寸法の長方形内に入るブロブまたはブロブのグループは破棄されます。
- CharSpacing:隣り合う文字の最小間隔の幅。この値がMaxCharWidthより大きいと、何も効果はありません。
文字の間隔がこれより大きい場合、2つの文字は異なる文字として見なされます。これにより、細い文字が間違ってグループ化されてしまうのを防げます。 - RemoveBorder:通常、画像/ROIのエッジ近くにあるブロブは文字認識に使用されません。デフォルトでは破棄されます。
各文字はフォントと呼ばれるパターンのセットと比較されます。そして文字とフォントのパターン間のベストマッチを見つけることで文字が認識されます。文字が特定されると、マッチングのためにサイズが正規化されます(事前定義された長方形に合わせて引き伸ばされます)。正規化された文字はフォントデータベース内の正規化されたテンプレートと比較され、ベストマッチが返されます。
- Load:事前に記録されたフォントをディスクファイルから読み取ります。
- BuildObjects:画像がオブジェクトまたはブロブ(繋がったコンポーネント) にセグメンテーションされます。これは文字の検出に役立ちます。文字の正確な位置が分かっている場合はこの手順を飛ばすことができます。文字分離プロセスを飛ばす場合、分かってる文字位置を指定しなければなりません:AddCharおよびEmptyChars。
- FindAllChars:文字と見なされるオブジェクトを選択し、上から下へ、そして左から右へ並べます。
- ReadText:マッチングを実行し、マークの構成が固定されている場合または文字セットフィルタがある場合は文字のフィルタリングが行われます。
文字認識:各文字はフォントと呼ばれるパターンのセットと比較されます。
事前定義されている長方形に合わせてベストマッチが引き伸ばされ、フォントデータベース内の正規化された各テンプレートと比較されます。
文字セットフィルタにより比較する文字範囲を制限することで、認識の信頼性を高めて実行時間を短縮できます。例えば、マークが常に2つの大文字と5つの数字から成り、末尾は必ず偶数の数字である場合、各文字にクラスを割り当てて(最大32クラス)、認識時に次のクラスを検出するための文字フィルタを設定します:大文字2つ、偶数または奇数の数字4つ、偶数の数字1つ。
2~4のステップを必要なだけ繰り返して、他の画像またはROIを処理します。Recognizeメソッドも使用できます。
検出された文字の幾何学位置などの追加情報は、CharGetOrgX、CharGetOrgY、CharGetWidth、CharGetHeightなどを使用して取得します。
CompareAspectRatioでは、幅が狭い文字と広い文字の違いを考慮して文字やフォントを比較します。それにより、サイズ正規化後の文字が互いに似ているときに認識精度が高まります。
- MaxCharWidth、MaxCharHeight:この寸法の長方形内に入らないブロブは文字と見なされず(大きすぎる)、除外されます。さらに、この寸法の長方形内に複数のブロブがある場合、それらはまとめてグループ化されて一つの文字を形成します。外側の長方形サイズは、小さい安全マージンで拡張して、フォントの中で最も大きい文字が収まるように選択する必要があります。
- MinCharWidth、MinCharHeight:この寸法の長方形内に入らないブロブまたはブロブのグループは文字と見なされず(小さすぎる)、除外されます。内側の長方形サイズは、小さい安全マージンで収縮して、フォントの中で最も小さい文字内に含まれるように選択する必要があります。
- RemoveNarrowOrFlat:小さい文字の幅が狭いかまたは平坦な場合、除外されます。デフォルトでは、幅が狭くかつ平坦な文字は除外されます。
- CharSpacing:2つのブロブ間にこの値より大きい縦方向の間隔がある場合、これらは異なる文字であると見なされます。この機能は、外側の長方形内にあつ複数の細い文字がグループ化されるのを防ぐ際に便利です。この値には隣り合う文字の最小間隔の幅を設定します。大きい値(MaxCharWidthより大きい値)が設定されていると、何も効果はありません。
- CutLargeChars:MaxCharWidthより大きいブロブまたはブロブのグループは除外されます。これを有効にすると、RelativeSpacingで設定された分割ブロブ間に挿入される白のスペースの大きさに応じてブロブが必要な数だけ分割されます。それにより接触している文字を分離します。
- RelativeSpacing:CutLargeCharsモードが有効であるとき、この値を設定することでブロブの分割部分の間に挿入される白のスペースの大きさを指定できます。

無効な認識の設定
認識を最適化するために次の認識パラメータを調整できます:
- オブジェクト保持モード:1文字が1つのブロブに当たります。ブロブのグループ化が行われないため、損傷した文字は処理不可能で、アクセントやドットなどの小さい形状は最小文字サイズの基準によって除外できます。
- オブジェクト再貼り付けモード:ブロブが最大文字サイズより小さく縦方向の間隔によって分離されていない場合、それらのブロブはグループ化されて個別の文字を形成します。 アクセントやドットも保持されます。