
EasyOCR2 - テキストの読み込み(改良版)
EasyOCR2は、ラベルまたは部品に印字されたシリアル番号、有効期限、ロット番号などの短い文字列を読み取るために設計された光学認識ライブラリです。
革新的なセグメンテーション手法を使用してイメージ内のブロブを検出し、ユーザー定義のトポロジ(テキスト内の行数、単語数、文字数)に従って検出されたブロブにテキストボックスを配置します。これらのメソッドは360度まで回転したテキストに対応し、不均一な照明、模様がある背景のほか、ドット印刷された文字や分断した文字も対処できます。
テキストに含まれる各文字の種類(文字、数字/記号)を指定することで、認識レートおよび速度を向上できます。認識に使用される文字データベースは、サンプル画像から学習したり、トゥルータイプフォントファイル (.ttf) から読み取ることができます。
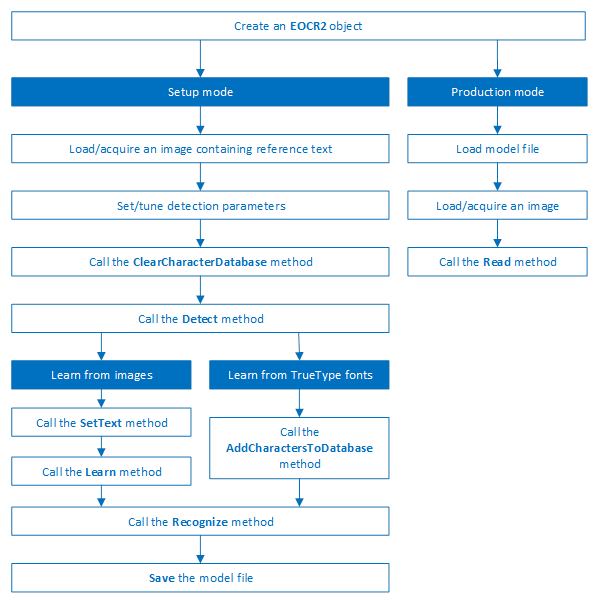
EasyOCR2でのテキスト認識は、次の4つの段階に従います。

入力画像(左)と画像分割(右)


フィッティングテキストボックス(左)と認識(右)
EasyOCR2は、EasyOCRよりも優れた結果を提供します。
| □ | 不明なテキストローテーション |
| □ | ドットまたは断片文字 |
| □ | 不均一な照明またはテクスチャ付きの背景 |
| ● | 読み取るテキストに一致するTrueTypeフォントファイルが使用可能な場合、EasyOCR2はユーザーが認識のためにこれらのフォントファイルを直接使用することを許可します。それに対してEasyOCRは許可しません。 |
| ● | 上記のいずれもアプリケーションに関係しない場合、ユーザーは、優れた計算速度のためにEasyOCRをEasyOCR2の使用を好む場合があります。 |
EasyOCR2は、次のように画像内の文字を検索します。
| 1. | EasyOCR2はイメージを分割し、文字の一部を表すブロブを見つけます。 |
| 2. | 文字の一部と見なすには大きすぎるか小さすぎるブロブは除外されます。 |
| 3. | EasyOCR2は、指定されたトポロジとdetectionMethodに従って、検出されたブロブに文字ボックスを合わせます。 |
トポロジは、イメージのテキストの構造を記述し、行数、行あたりの単語数、および単語あたりの文字数を定義します。
| 4. | EasyOCR2は、画像から各文字ボックス内のピクセルを抽出します。 |
結果として得られる文字イメージを使用して、文字を学習または認識することができます。
イメージ内のテキストを検出するワークフローは、次のようになります。
| a. | 必要な検出パラメータを設定します。 |
| b. | または、Loadを呼び出して、ディスクから検出パラメータを含むあらかじめ作成されたモデル(.o2m)ファイルを読み込みます。 |
| c. | 画像からテキストを抽出するためにDetectを呼び出します。 |
Detectメソッドは、EOCR2Line -> EOCR2Word -> EOCR2Char構造体に階層的に保存された各文字のテキストボックスとビットマップイメージを含むEOCR2Text構造体を戻します。
コードスニペットの例を参照してください。 Detecting Characters

detectionMethod ‘EOCR2DetectionMethod_FixedWidth’で処理された固定幅フォントの例

detectionMethod ‘EOCR2DetectionMethod_Proportional’で処理された固定幅フォントの例

NumDetectionPasses = 1の場合、この画像のtextAngle推定値は少しオフになります

NumDetectionPasses= 2の場合、textAngleの推定値が優れています

このドット付きテキストの場合、 CharsMaxFragmentationを0.1に設定すると、セグメント化の結果が不完全になります

CharsMaxFragmentationを0.01に設定すると、より良いセグメンテーション結果が得られます
必要なパラメータ
| □ | パラメータTopologyは、ボックスフィッティングメソッドに、検出されたブロブに適合するテキストボックスをどのように構造化するかを指示します。Regex式の修正バージョンを使用して、トポロジは、テキスト内の行数、行あたりの単語数、および単語あたりの文字数を決定します。認識パラメータセクションには、トポロジの構文の詳細な説明が含まれています。 |
| □ | このパラメータCharsWidthRangeは、画像内の文字がどのくらい幅広くできるか、セグメンテーションと検出方法に指示します。 |
| □ | このパラメータCharsHeightは、画像内の文字がどのくらい高くできるか、セグメンテーションと検出方法に指示します。 |
| □ | このパラメータTextPolarityは、セグメンテーションメソッドに、暗い背景で明るい文字を探すべきかどうか指示します。 |
セグメンテーションのための高度なパラメータ(オプション):
| □ | CharsMaxFragmentationパラメータは、セグメンテーションアルゴリズムに、小さなブロブを文字の一部と見なすことができるかどうかを指示します。ブロブの最小許容領域は、次の式で与えられます。 |
minArea = CharsMaxFragmentation * CharsHeight * min(CharsWidthRange)
このパラメータは0と1の間で設定する必要があります。デフォルト設定は0.1です。
| □ | MaxVariationパラメータは、潜在的な文字と見なされるためにイメージ内のブロブがどのくらい安定しているべきかを決定します。 |
明確に定義されたエッジを有する領域は一般的には安定し、ぼやけた領域は安定していないと考えられます。高い設定では不安定なブロブを検出でき、低い設定では非常に安定したブロブしか検出できません。
このパラメータは0と1の間で設定する必要があります。デフォルト設定は0.25です。
| □ | DetectionDeltaパラメータは、BLOBの安定性を決定するために使用されるグレースケール値の範囲を決定します。 |
設定が低いと、アルゴリズムはノイズに対してより敏感になります。高い設定を指定すると、背景とのコントラストが低いブロブに対してアルゴリズムが鈍感になります。
このパラメータは1と127の間で設定する必要があります。デフォルト設定は12です。
検出のための高度なパラメータ(オプション)
| □ | このパラメータDetectionMethodは、フィッティングに使用されるアルゴリズムを選択します。EOCR2DetectionMethod_FixedWidth(デフォルト)の設定は、固定幅フォント(点線のテキストを含む)のテキストに最適化されています。設定EOCR2DetectionMethod_Proportionalは、比例フォントのテキストに最適化されています。 |
| □ | TextAngleRangeパラメータは、画像のテキストの向きをボックスフィッティング方法に指示します。次の範囲の回転角度をテストします。 |
min(TextAngleRange) ≤ angle ≤ max(TextAngleRange)
角度は水平に対して定義されます。角度(度/ラジアン/回転/等級)の単位は、easy :: SetAngleUnit()を使用して設定できます。
このパラメータのデフォルト設定は[-20、20]度です。
| □ | パラメータNumDetectionPassesは、検出されたブロブにテキストボックスを収めるためにいくつのパスが行われるかを決定します。最初のパスは、検出されたすべてのブロブにテキストボックスを合わせます。後続のパスは、前回のパスからテキストボックスでカバーされたブロブのみを選択し、そのブロブのサブセットにテキストボックスを合わせることで、より最適なフィットが得られる可能性があります。 |
このパラメータは1または2に設定する必要があります。デフォルト設定は1です。
設定に固有の高度なパラメータEOCR2DetectionMethod_FixedWidth
| □ | RelativeSpacesWidthRangeパラメータは、単語間のスペースがどのくらい広がっているかをボックスフィット方法に指示します。次の範囲のスペースをテストします。 |
min(SpacesWidthRange) * charWidth ≤ space ≤ max(SpacesWidthRange) * charWidth
| □ | パラメータCharsWidthBiasは、幅の狭い文字ボックスに向かって最適化をバイアスします。 |
| □ | パラメータCharsSpacingBias は、最適化を文字ボックス間より狭いまたは広い間隔に偏らせます。 |
付言
| □ | EOCR2DetectionMethod_FixedWidthの設定を選択すると、すべての文字ボックスの幅が同じになり、必ずしも文字の周りにぴったりフィットする必要はありません。 |
| □ | EOCR2DetectionMethod_Proportionalを選択すると、文字ボックスが文字の周りにぴったりフィットし、文字が許容文字幅の範囲外にある場合、検出は失敗します。 |
文字を認識するために、EasyOCR2には既知の参照文字のデータベースが必要です。画像やTrueTypeシステムフォントからこの文字データベースを作成する可能性があります。
文字のデータベース作成のワークフローは、次のようになります。
| a. | 必要な検出パラメータを設定するか、Model(.o2m)ファイルをディスクから読み込むためにLoadを呼び出します。 |
| b. | 必要に応じて、ClearCharacterDatabaseを呼び出して現在の文字データベースをクリアします。 |
| c. | 画像からテキストを抽出するためにDetectを呼び出します。 |
| d. | 抽出されたテキスト構造のSetTextを呼び出して、各文字の正しい値を設定します。 |
| e. | Learnを呼び出して、検出された文字とその正しい値を現在の文字データベースに追加します。 |
| f. | SaveCharacterDatabaseを呼び出して、現在の文字データベースをディスクに保存します。 |
| g. | または、Saveを呼び出して、検出パラメータと作成された文字データベースを含むモデルファイルをディスクに保存します。 |
コードスニペットの例を参照してください。 Learning Characters
EasyOCR2は、文字データベースで訓練された分類子を使用して文字を認識します。各入力文字について、分類器はすべての候補出力のスコアを計算し、最高スコアを有する候補が認識結果として戻されます。Topologyパラメータを通して、各文字に関する事前情報を分類子に渡すことができ、候補の数を減らし、認識率を向上させることができます。
画像からテキストを認識するための制作ワークフローは、次のようになります。
| □ | Loadを呼び出して、モデル(.o2m)ファイルをディスクから読み込みます。モデルファイルには、すべての検出パラメータ、トポロジおよび参照文字データベースが含まれています。 |
| □ | イメージをロードまたは取得します。 |
| □ | 文字を検出して認識するためにReadを呼び出します。 |
| □ | または、Detectを呼び出してイメージからテキストを抽出し、Recognizeを実行して抽出されたテキストを認識します。これにより、ユーザは、必要に応じて、認識される前に検出されたテキストの要素を変更することができます。 |
ReadとRecognizeメソッドは、認識結果を含む文字列を戻します。結果に関する詳細な情報にアクセスするには、ReadTextを呼び出すことができます。これは、各テキストボックスの座標とサイズだけでなく、ビットマップイメージと各文字の認識スコアのリストを含むEOCR2Text構造体を戻します。
コードスニペットの例を参照してください。 Reading Characters
認識パラメータ
Topologyパラメーターは、テキストの構造(行数/語数/文字数)と、テキスト内の文字の種類を指定します。認識方法は、与えられたトポロジーに基づいて各文字の候補の数を制限します。
変更された正規表現のワイルドカードを使用します。
| □ | 「.」(ドット)は任意の文字(スペースを含まない)を表します。 |
| □ | 「L」はアルファベット文字を表します。 |
- 「Lu」はアルファベットの大文字を表します。
- 「L1」は小文字のアルファベット文字を表します。
| □ | 「N」は数字を表します。 |
| □ | 「N」は数字を表します。 「P」は次の区切り文字を表します:! “ # % & ‘ ( ) * , - . / : ; < > ? @ [ \ ] _ { | } ~ |
| □ | 「S」は次の記号を表します:$ + - < = > | ~ |
| □ | 「\n」は改行を表します。 |
| □ | 「 」(スペース)は2つの単語間のスペースを表します。 |
組み合わせることができます。例えば、[LN]は英数字を表します。複数の文字を指定するには、文字の最後に {n} を追加するだけです。文字の量が不明な場合は、最小のの文字と最大mの文字に{n、m}を指定します。
トポロジ「[LuN] {3,5} PN {4} \ n。{5} LL」は、2行からなるテキストを表します。
| □ | 最初の行には、3〜5文字の大文字の英数字で構成された1語と、その後に句読点と4桁の数字が続きます。 |
| □ | 2行目は2ワードです。最初の単語は5つのワイルドカード文字で構成され、2番目の単語は2つの文字(大文字または小文字)で構成されます。 |
トポロジ “L{3}P N{6} \n L{3}P NNPN{4}” は2行のテキストを表します。
| □ | 1行目は2ワードです。最初の単語には3つの大文字と句読記号が続き、2番目の単語には6桁の数字があります。 |
| □ | 2行目にも2つの単語があります。最初の単語には3つの大文字と句読点が続きます。2番目の単語は2桁で、その後に句読記号と4桁の数字が続きます。 |
トポロジ“.{10} \n .{7} \n .{5} .{5} \n .{5} .{7}”は4行のテキストを表します。
| □ | 最初の行には10文字(ASCII)文字の1語が含まれています |
| □ | 2行目には7文字の単語が1つ含まれています |
| □ | 3行目には、それぞれ5文字の2つの単語が含まれています。 |
| □ | 4行目には、それぞれ5文字と7文字の2単語が含まれています。 |