
EasyOCR 光学字符识别库读取短文本(如序列号、部件号和日期)。
它使用具有模板匹配算法的字体文件(预定义的 OCR-A、OCR-B 和 Semi 标准字体或其他学习的字体),可以识别任何大小的甚至打印不好、断开或连接的字符。
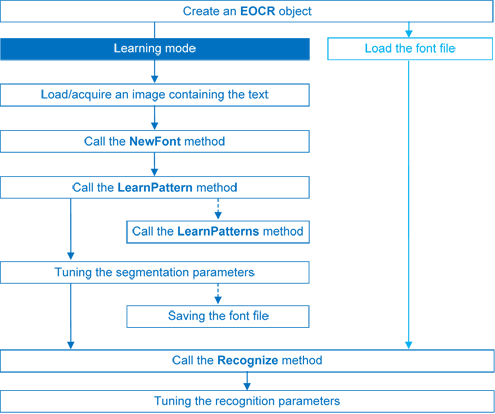
识别字符有 4 个步骤:
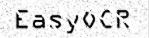
|
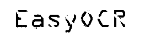
|
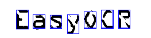
|
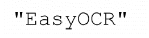
|
| 1. 原始图像 | 2. 对象分割 | 3. 字符隔离 | 4. 字符识别 |
如果需要,可以学习字符来创建字体文件。
字符被逐个呈现给 EasyOCR,它分析它们并构建一个称为字体的字符数据库。每个字符都有一个数字代码(通常是其 ASCII 码),属于字符类(可用于识别过程)。
字体文件创建如下:
- NewFont 清除当前字体。
- LearnPattern 或 LearnPatterns 将图案从源图像添加到字体。
按照由 FindAllChars 进程分配的索引值对图案进行排序。
字体中的图案被存储为一小部分像素,默认为 5 像素宽,9 像素高。使用参数 PatternWidth 和 PatternHeight,可以在学习之前更改该尺寸。 - RemovePattern 删除不需要的图案(可选)。
- Save 将字体的内容写入具有参数值的磁盘文件: NoiseArea、MaxCharWidth、MaxCharHeight、MinCharWidth、MinCharHeight、CharSpacing、TextColor。
- EasyOCR 使用两种分割模式中的一种来分析斑点以查找字符及其边界框:
- 保留对象模式:一个斑点对应一个字符。
- 重复粘贴对象模式:斑点被分组成公称大小的字符。当字符被破坏或由几个部分组成时,这是有用的。当一个斑点太大而不能被当作一个字符时,可以使用 CutLargeChars 对它进行自动分割。
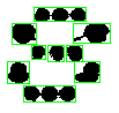
![]()
通过斑点分组进行字符分割
2. 过滤器去除非常大和非常小的不需要的特征。
3. EasyOCR 处理字符图像以将大小归一化为边框,提取相关功能,并将其存储在字体文件中。字体中的图案存储为由 PatternWidth 和 PatternHeight 定义的像素数组(默认为 5 像素宽,9 像素高)。
在学习和识别过程中,分割参数必须相同。良好的分割改善了识别。
- 阈值参数有助于将文本与背景区分开来。
太高的值会增加白色背景上的黑色字符,并可能导致合并,太小的值会使各部分消失。
如果照明条件易于变化,自动设置阈值是一个不错的选择。



阈值过高(左)、阈值调整(中)、阈值过低(右)
- NoiseArea: 小于该值的斑点区域被丢弃。确保保留小字符特征(即,“i”字母上的点)。
- MaxCharWidth、MaxCharHeight: 最大字符大小。如果斑点不适合具有这些尺寸的矩形,则使用垂直切割线将其丢弃或分割成多个部分。如果几个斑点适合具有这些尺寸的矩形,则它们被组合在一起。
- MinCharWidth、MinCharHeight: 最小字符大小。如果一个斑点或一组斑点适合具有这些尺寸的矩形,则会被丢弃。
- CharSpacing: 相邻字母之间最小间隙的宽度。如果大于 MaxCharWidth ,则不起作用。
如果两个字符之间的差距比这更宽,则被视为不同的字符。这样可以防止细小的字符被不正确地分组在一起。 - RemoveBorder: 图像/ROI 边缘附近的斑点通常不能被用于字符识别。默认情况下,它们被丢弃。
将字符与一组图案(称为字体)进行比较。通过在字体中找到字符和图案之间的最佳匹配来识别字符。在找到字符之后,它被归一化大小(拉伸以适合预定矩形)以进行匹配。将归一化字符与字体数据库中的每个归一化模板进行比较,并返回最佳匹配。
- Load:从磁盘文件读取预先录制的字体。
- BuildObjects:图像被分割成对象或者斑点(连接的组件),这有助于找到字符。如果字符的确切位置已知,则可以忽略此步骤。如果绕过了字符隔离进程,则必须指定字符的已知位置:AddChar和EmptyChars。
- FindAllChars: 选择被视为字符的对象,并从上到下,然后从左到右对它们进行排序。
- ReadText: 如果标记结构固定或提供了字符集过滤器,则执行匹配和过滤字符。
字符识别:将字符与一组图案(称为字体)进行比较。
最佳匹配被拉伸以适应预定义的矩形,并与字体数据库中的每个归一化模板进行比较。
字符集过滤器可以通过限制要比较的字符范围来提高识别可靠性和运行时间。例如,如果标记总是由两个大写字母组成,后跟五位数,最后一个字母始终为偶数,则可以为每个字符分配一个类(最多 32 个类),然后设置字符过滤器,以在识别时允许以下类:两个大写,四个偶数或奇数,一个偶数位。
步骤 2 到 4 可以随意重复处理其他图像或 ROI。也可以使用 Recognize 方法。
附加信息,例如检测到的字符几何位置,可以使用以下方式获得:CharGetOrgX、CharGetOrgY、CharGetWidth、CharGetHeight...
CompareAspectRatio 使字符和字体比较对窄和宽字符之间的差异敏感。当尺寸归一化后字符看起来相似,可以改善识别。
- MaxCharWidth、MaxCharHeight: 如果一个斑点不适合具有这些尺寸的矩形,则它不被认为是可能的字符(太大)并被丢弃。此外,如果几个斑点适合具有这些尺寸的矩形,则它们被分组在一起,形成单个字符。应选择外部矩形尺寸,使其可以包含字体中最大的字符,并以较小的安全余量放大。
- MinCharWidth、MinCharHeight: 如果一个斑点或一组斑点适合具有这些尺寸的矩形,则不会将其视为可能的字符(太小)并被丢弃。应该选择内部矩形尺寸,使其包含在字体的最小字符中,缩小安全幅度。
- RemoveNarrowOrFlat: 如果小字符狭窄或平坦,则会被丢弃。默认情况下,当狭窄且平坦时,它们将被丢弃。
- CharSpacing: 如果两个斑点之间的距离大于该值,则它们被认为属于不同的字符。该功能有助于避免对适合外部矩形的瘦字符进行分组。其值应设置为相邻字母之间最小间隙的宽度。如果它设置为一个较大的值(大于 MaxCharWidth),它没有任何效果。
- CutLargeChars:当斑点或斑点组合大于 MaxCharWidth 时,它将被丢弃。启用时,斑点会根据需要被分割成尽可能多的部分,以便在 RelativeSpacing 之间设置插入分割块之间的空白空间。这是试图分离触摸字符的一次尝试。
- RelativeSpacing: 当启用 CutLargeChars 模式时,设置此值可以指定在斑点的分割部分之间应插入的空白空间量。

无效的识别设置
可以调整这些识别参数以优化识别:
- 保留对象模式:一个字符是一个斑点;没有尝试对斑点进行分组,因此不能处理损坏的字符,并且可以通过最小字符尺寸标准丢弃诸如重音符号和圆点的小特征。
- 重复粘贴对象模式:如果斑点符合最大字符大小,并且没有被垂直间距分隔,它们会被分组以构成不同的字符,从而保留重音符号和圆点。