
EasyOCR2 - Reading Texts (Improved)
EasyOCR2 is an optical recognition library designed to read short texts such as serial numbers, expiry dates or lot codes printed on labels or on parts.
It uses an innovative segmentation method to detect blobs in the image, and then places textboxes over the detected blobs following a user-defined topology (number of lines, words and characters in the text). These methods support text rotation up to 360 degrees, can handle non-uniform illumination, textured backgrounds, as well as dot-printed or fragmented characters.
A character type (letter / digit / symbol) can be specified for each character in the text, improving recognition rate and speed. The character database that is used for recognition can be learned from sample images or read from a TrueType font (.ttf) file.
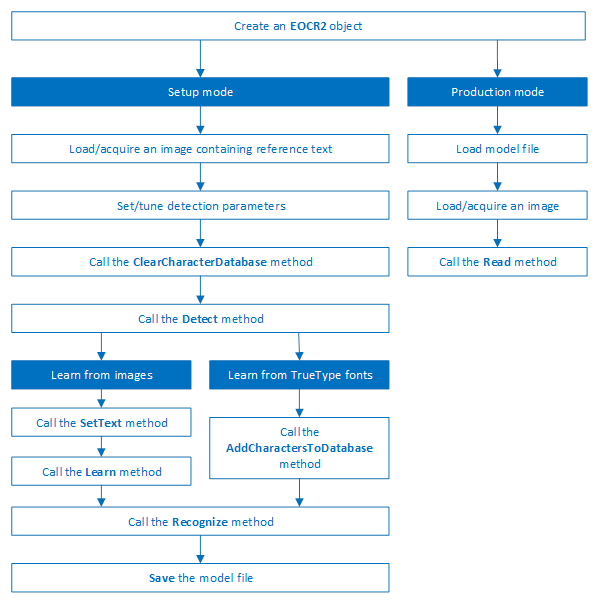
Text recognition with EasyOCR2 follows four phases:

Input image (left) and fitting textboxes (right)


Image segmentation (left) and recognition (right)
EasyOCR2 will give better results than EasyOCR when dealing with:
| □ | Unknown text rotation |
| □ | Dotted or fragmented characters |
| □ | Non-uniform illumination or textured backgrounds |
| ● | When TrueType font files are available that match the text to be read, EasyOCR2 allows the user to use those font files directly for recognition, while EasyOCR does not. |
| ● | When none of the above are relevant to the application, the user may prefer to use EasyOCR to EasyOCR2 due to its superior computational speed. |
EasyOCR2 finds characters in an image as follows:
| 1. | EasyOCR2 segments the image, finding blobs that represent (parts of) the characters. |
| 2. | Blobs that are too large or too small to be considered part of a character are filtered out. |
| 3. | EasyOCR2 fits character boxes to the detected blobs according to a given topology and detectionMethod. |
The topology describes the structure of the text in the image, defining the number of lines, the number of words per line and the number of characters per word.
| 4. | EasyOCR2 extracts the pixels inside each character box from the image. |
The resulting character-images can be used to learn or recognize the characters.
A workflow detecting text in an image could be as follows:
| a. | Set the required detection parameters. |
| b. | Alternatively, call Load to read a pre-made model (.o2m) file containing detection parameters from disk. |
| c. | Call Detect to extract the text from the image. |
The method Detect will return an EOCR2Text structure that contains a textbox and a bitmap image for each character, hierarchically stored in EOCR2Line -> EOCR2Word -> EOCR2Char structures.
See example in code snippet: Detecting Characters

An example of a fixed-width font, processed with the detectionMethod ‘EOCR2DetectionMethod_FixedWidth’

An example of a proportional font, processed with the detectionMethod ‘EOCR2DetectionMethod_Proportional’

The textAngle estimate for this image is slightly off when NumDetectionPasses=1

The textAngle estimate is better when NumDetectionPasses=2

For this dotted text, setting 'CharsMaxFragmentation' to 0.1 leads to incomplete segmentation results

Setting 'CharsMaxFragmentation' to 0.01 gives better segmentation results
Required parameters
| □ | The parameter Topology tells the box-fitting method how to structure the textboxes it fits to the detected blobs. Using a modified version of Regex expressions, the topology determines the number of lines in the text, the number of words per line and the number of characters per word. The section Recognition Parameters contains an extensive explanation of the syntax for the Topology. |
| □ | The parameter CharsWidthRange tells the segmentation and detection methods how wide the characters in the image can be. |
| □ | The parameter CharsHeight tells the segmentation and detection methods how high the characters in the image can be. |
| □ | The parameter TextPolarity tells the segmentation method whether it should look for light characters on a dark background or vice versa. |
Advanced parameters for segmentation (optional):
| □ | The CharsMaxFragmentation parameter tells the segmentation algorithm how small blobs can be to be considered (part of) a character. The minimum allowed area of a blob is given by: |
minArea = CharsMaxFragmentation * CharsHeight * min(CharsWidthRange)
This parameter should be set between 0 and 1, the default setting is 0.1.
| □ | The MaxVariation parameter determines how stable a blob in the image should be in order to be considered a potential character. |
A region with clearly defined edges is generally considered stable while a blurry region is not. A high setting allows detection of blobs that are more unstable, a low setting allows only very stable blobs.
This parameter should be set between 0 and 1, the default setting is 0.25.
| □ | The DetectionDelta parameter determines the range of grayscale values used to determine the stability of a blob. |
A low setting will make the algorithm more sensitive to noise; a high setting will make the algorithm insensitive to blobs with low contrast to the background.
This parameter should be set between 1 and 127, the default setting is 12.
Advanced parameters for detection (optional)
| □ | The parameter DetectionMethod selects the algorithm used for fitting. The setting EOCR2DetectionMethod_FixedWidth (default) is optimized for texts with fixed width fonts (including dotted text), the setting EOCR2DetectionMethod_Proportional is optimized for texts with proportional fonts. |
| □ | The TextAngleRange parameter tells the box-fitting method how the text in the image is oriented. It will test the following range of rotation angles: |
min(TextAngleRange) ≤ angle ≤ max(TextAngleRange)
where angles are defined with respect to the horizontal. The unit for the angles (degrees/radians/revolutions/grades) can be set using easy::SetAngleUnit().
The default setting for this parameter is [-20, 20] degrees.
| □ | The parameter NumDetectionPasses determines how many passes are made to fit textboxes to the detected blobs. The initial pass will fit textboxes to all detected blobs. Subsequent passes will select only those blobs that are covered by the textboxes from the previous pass and fit textboxes to that subset of blobs, potentially resulting in a more optimal fit. |
This parameter should be set to either 1 or 2, the default setting is 1.
Advanced parameters, specific for the setting EOCR2DetectionMethod_FixedWidth
| □ | The RelativeSpacesWidthRange parameter tells the box-fitting method how wide the spaces between words may be. It will test the following range of spaces: |
min(SpacesWidthRange) * charWidth ≤ space ≤ max(SpacesWidthRange) * charWidth
| □ | The parameter CharsWidthBias biases the optimization toward wider of narrower character boxes. |
| □ | The parameter CharsSpacingBias biases the optimization toward smaller or larger spacing between characters boxes. |
Additional remarks
| □ | When the setting EOCR2DetectionMethod_FixedWidth is selected, all character boxes will have the same width and they do not necessarily have to fit tightly around the characters. |
| □ | When the setting EOCR2DetectionMethod_Proportional is selected, the character boxes will fit tightly around the characters, if any character falls outside the range of allowed character widths, the detection will fail. |
In order to recognize characters, EasyOCR2 requires a database of known reference characters. We may generate this character database from images and/or from TrueType system fonts.
A workflow to build a character database could be as follows:
| a. | Set the required detection parameters or call Load to read the model (.o2m) file from disk. |
| b. | Optionally, call ClearCharacterDatabase to clear the current character database. |
| c. | Call Detect to extract the text from the image. |
| d. | Call SetText in the extracted text structure to set the correct value for each character. |
| e. | Call Learn to add the detected characters and their correct value to the current character database. |
| f. | Call SaveCharacterDatabase to save the current character database to disk. |
| g. | Alternatively, call Save to save the model file to disk, including the detection parameters and the created character database. |
See example in code snippet: Learning Characters
EasyOCR2 recognizes characters using a classifier that is trained on the character database. For each input character, the classifier will calculate a score for all candidate outputs, the candidate with the highest score will be returned as the recognition result. Through the Topology parameter, prior information about each character can be passed to the classifier, reducing the number of candidates and improving the recognition rate.
The production workflow for recognizing text from images could be as follows:
| □ | Call Load to read the model (.o2m) file from disk. The model file contains all detection parameters, as well as the topology and the reference character database. |
| □ | Load or acquire the image. |
| □ | Call Read to detect and recognize the characters. |
| □ | Alternatively, call Detect to extract the text from the image, followed by Recognize to recognize the extracted text. This allows the user to modify elements of the detected text before recognition if so desired. |
The methods Read and Recognize will return a string with the recognition results. To access more in-depth information about the results, one may call ReadText. This returns an EOCR2Text structure that contains the coordinates and sizes of each textbox as well as a bitmap image and a list of recognition scores for each character.
See example in code snippet: Reading Characters
Recognition parameters
The Topology parameter specifies the structure of the text (number of lines/words/characters) as well as the type of characters in the text. The recognition method will limit the number of candidates for each character based on the given topology.
It uses modified regular expression wildcards:
| □ | “.” (dot) represents any character (not including a space). |
| □ | “L” represents an alphabetic character. |
- “Lu” represents an uppercase alphabetic character.
- “Ll” represents a lowercase alphabetic character.
| □ | “N” represents a digit. |
| □ | “P” represents the punctuation characters: ! “ # % & ‘ ( ) * , - . / : ; < > ? @ [ \ ] _ { | } ~ |
| □ | “S” represents the symbols: $ + - < = > | ~ |
| □ | “\n” represents a line break. |
| □ | “ ” (space) represents a space between two words. |
Combinations can be made, for example: [LN] represents an alpha-numeric character. To specify multiple characters, simply add {n} at the end for n characters. If the amount of characters is uncertain, specify {n,m} for a minimum of n characters and a maximum of m characters.
The topology “[LuN]{3,5}PN{4} \n .{5} LL” represents a text comprised of 2 lines:
| □ | The first line has 1 word composed of 3 to 5 uppercase alpha-numeric characters, followed by a punctuation character and 4 digits. |
| □ | The second line has 2 words. The first word comprises of 5 wildcard characters, the second word has 2 letters (upper- or lowercase). |
The topology “L{3}P N{6} \n L{3}P NNPN{4}” represents a text with 2 lines:
| □ | The first line has 2 words. The first word has 3 uppercase letters followed by a punctuation mark, the second word has 6 digits. |
| □ | The second line also has two words. The first word has 3 uppercase letters followed by a punctuation mark. The second word has 2 digits, followed by a punctuation mark and 4 additional digits. |
The topology “.{10} \n .{7} \n .{5} .{5} \n .{5} .{7}” represents a text with 4 lines:
| □ | The first line contains a single word of 10 (ASCII) characters |
| □ | The second line contains a single word of 7 characters |
| □ | The third line contains two words, each of 5 characters. |
| □ | The fourth line contains two words of 5 and 7 characters respectively. |