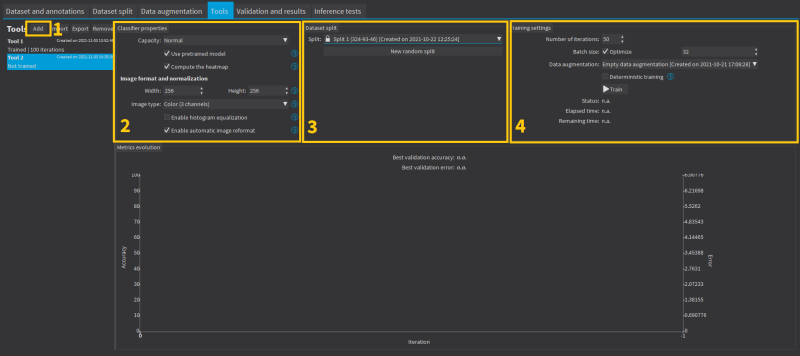
Training a Deep Learning Tool
In Deep Learning Studio
|
2.
|
Configure the tool settings. |
|
3.
|
Select the dataset split to use for this tool. |
|
4.
|
Configure the training settings and click on Train. |
The training settings
|
●
|
The Number of iterations. An Iteration corresponds to going through all the images in the training set once. |
|
□
|
The training process requires a large number of iterations to obtain good results. |
|
□
|
The larger the number of iterations, the longer the training is and the better the results you obtain. |
|
□
|
The default number of iterations is 50. |
We recommend to use more iterations than the default value:
|
□
|
For EasyClassify without pretraining, EasyLocate and EasySegment. |
|
□
|
For smaller dataset because the training is harder (for example, 100 iterations for a dataset with 100 images, 200 iterations for a dataset with 50 images, 400 iterations for a dataset with 25 images...). |
|
●
|
The Batch size corresponds to the number of image patches that are processed together. |
|
□
|
The training is influenced by the batch size. |
|
□
|
A large batch size increases the processing speed of a single iteration on a GPU but requires more memory. |
|
□
|
The training process is not able to learn a good model with too small batch sizes. |
|
□
|
It is common to choose powers of 2 as the batch size for performance reasons. |
|
●
|
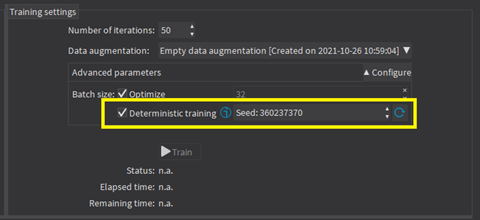
Whether to use Deterministic training or not. |
|
□
|
The deterministic training allows to reproduce the exact same results when all the settings are the same (tool settings, dataset split and training settings). |
|
□
|
The deterministic training fixes random seeds used in the training algorithm and uses deterministic algorithms. |
|
□
|
The deterministic training is usually slower than a non-deterministic training. |
|
□
|
In Deep Learning Studio, the option to use deterministic training and the random seed are available in the advanced parameters. |
Continue the training
You can continue to train a tool that is already trained.
In Deep Learning Studio, the dataset split associated with a trained tool is locked.
|
□
|
You can only continue training a tool with the same dataset split. |
|
□
|
You can still add new training or validation images to the split by moving test images to the training set or the validation set of that split. |
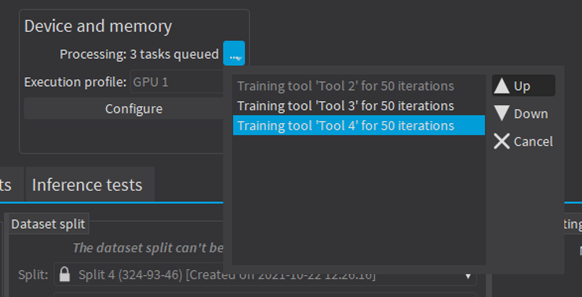
Asynchronous training
The training process is asynchronous and performed in the background.
|
●
|
In Deep Learning Studio: |
|
□
|
The training processes are queued. |
|
□
|
They are automatically executed one after the other. |
|
□
|
You can manually reorder the training in the processing queue. |