Engines
| ● | Starting with Open eVision 23.04, running (inference) or training a Deep Learning tool is done through an engine. The engines are specified through their names. |
| □ | To set an engine for a tool, use EDeepLearningTool.Engine |
| □ | To list the available engines, use EDeepLearningTool.AvailableEngines |
| ● | An engine can support different devices: |
| □ | To list the detected devices for the current engine, use EDeepLearningTool.AvailableDevices |
| □ | To list the detected devices for another engine, use EDeepLearningTool.GetAvailableDevicesForEngine. Note that this actually loads the engine in memory. |
| □ | The devices are represented by the class EDeepLearningDevice or directly through their name (EDeepLearningDevice.Name) that are guaranteed to be unique for a given engine. |
| □ | To set a device, use EDeepLearningTool.ActiveDevices or EDeepLearningTool.ActiveDevicesByName. You can pass multiple devices for multi-GPU training for example. |
| □ | To know if a device supports inference and/or training, use EDeepLeanringDevice.HasInferenceCapability and EDeepLearningDevice.HasTrainingCapability. Check the matrix below for each engine and device type support. |
| ● | A device or an engine can support various inference precision (FLOAT32 or FLOAT16). |
| □ | By default, the precision is FLOAT32. |
| □ | Use EDeepLearningTool.InferencePrecision to set or retrieve the current precision. |
| □ | A lower precision (for example FLOAT16 instead of FLOAT32) can improve the speed. |
| ● | The main engine is named default: |
| □ | It is always available and always supports the CPU of the computer on which it is running. |
| □ | It always supports both inference and training. |
| ● | The other engines: |
| □ | They are mainly used to increase the inference speed. |
| □ | The other engines and the support for a GPU are provided by the package named deep-learning-redist (previously cuda-redist). |
|
Engine name |
Supported devices |
Supported platforms |
Training |
Inference |
Inference precision |
|---|---|---|---|---|---|
|
default |
CPU NVIDIA GPU * |
All ** |
Yes |
Yes |
FLOAT32 |
|
EasyDeepLearningEngine_OpenVINO * |
CPU Intel GPU |
Windows 64-bit |
No |
Yes |
FLOAT16
|
|
EasyDeepLearningEngine_TensorRT * |
NVIDIA GPU |
Windows 64-bit |
No |
Yes |
FLOAT16
|
* Requires the deep-learning-redist package
** The Windows 32-bit support is only for CPU and the limitation to 2 GB of the application memory can be a problem for the training or the inference on large images.
The engine setup data
The initialization of some engines can take quite a long time (for example the TensorRT engine can take up to a few minutes to initialize).
To avoid having to perform this initialization each time you load the Deep Learning tool when your execution device, inference precision and batch size do not change, use the “engine setup data”.
| ● | To save the “engine setup data” along with your Deep Learning tool, save your tool after calling EDeepLearningTool.InitializeInference or after making an inference with it. |
In the API:
| ● | Check whether the tool has “engine setup data” with EDeepLearningTool.HasEngineSetupData. |
| ● | Check the execution settings for which the”engine setup data” are for with: |
| □ | For the device: EDeepLearningTool.EngineSetupDataDevice |
| □ | For the inference precision: EDeepLearningTool.EngineSetupDataInferencePrecision |
| □ | For the batch size: EDeepLearningTool.EngineSetupDataBatchSize |
In Deep Learning Studio
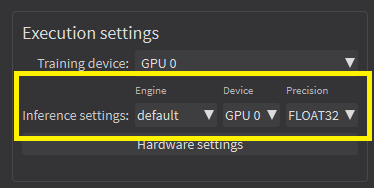
| ● | In the Execution settings panel, select the Engine, Device and Precision that you want to use for inference. |
Legacy API for selecting CPU and GPU
| ● | The API calls EDeepLearningTool.EnableGPU and EDeepLearningTool.GPUIndexes are deprecated. |
| ● | They can only be used with the default engine, otherwise, an exception is thrown. |
Additional consideration for NVIDIA CUDA® GPU
Using a recent NVIDIA GPU greatly accelerates the processing speeds. Refer to the benchmarks for each tool type to compare the GPU and CPU speeds.
To use an NVIDIA GPU with the Deep Learning tools, install the deep-learning-redist package for your operating system. It is not recommended to use a system-wide installation of the CUDA libraries for GPU support.
| 1. | To use an NVIDIA GPU with the Deep Learning tools, install the deep-learning-redist package for your operating system. |
It is not recommended to use a system-wide installation of the CUDA libraries for the GPU support.
In this version of Open eVision, the GPU acceleration is based on:
| □ | For Windows and Linux Intel x64: |
- NVIDIA CUDA® Toolkit version v11.8
- NVIDIA CUDA® Deep Neural Network library (cuDNN) v8.6
| □ | For Linux ARM (aarch64 Jetson platforms): |
- The CUDA and cuDNN packages distributed with the platforms.
The following versions have been tested:
- JetPack 4.6 (L4T 32.6.1)
- JetPack 5.0 (L4T 34.1)
- JetPack 5.1.2 (L4T 35.4.1)
| 2. | Check that you have or install the up-to-date NVIDIA drivers. |
| 2 | Refer to your GPU documentation to install recent drivers for your operating system. |
| 3. | For Linux ARM (aarch64 Jetson platforms), install the NVIDIA JetPack SDK 4.6 minimum that includes the NVIDIA Jetson Linux Driver Package (L4T) 32.6. |
Starting from NVIDIA JetPack SDK 4.3, it is possible to upgrade without flashing the device to the version 32.6 of the NVIDIA Jetson Linux Driver Package:
| □ | Edit the file /etc/apt/sources.list.d/nvidia-l4t-apt-source.list so that its content is: |
deb https://repo.download.nvidia.com/jetson/common r32.6 main
deb https://repo.download.nvidia.com/jetson/t194 r32.6 main
| □ | Upgrade the system using apt: |
$ sudo apt update
$ sudo apt upgrade
| 4. | Use the engine default for training and inference or the engine EasyDeepLearningEngine_TensorRT for inference only. |
For recent NVIDIA GPUs or Jetson Orin boards (NVIDIA GPUs with a compute capability higher than 8.0 on Intel x64 and 7.2 on aarch64), using Deep Learning triggers a long initialization (over a minute).
To avoid this initialization each time you use Deep Learning, we recommend to increase the CUDA cache max size to 1024 MB:
| ● | On Linux, set the environment variable CUDA_CACHE_MAXSIZE to 1073741824 before launching Deep Learning Studio or your program. |
In a terminal, this means executing:
$ CUDA_CACHE_MAXSIZE=1073741824 /path/to/your/program
| ● | On Windows, launch the Advanced System settings, go to the Environment variables dialog and add or modify the CUDA_CACHE_MAXSIZE variable with the value 1073741824. |
Using multiple GPUs
You can use multiple NVIDIA GPUs with the default engine for the training and the batch classification by specifying multiple NVIDIA GPUs devices with EDeepLearningTool.ActiveDevices.
Be careful to only set multiple GPUs that have similar performances: the performances are limited by the slowest device.
| ● | Using multiple GPUs increases the training and batch classification speed only if these GPUs are Quadro or Tesla models with the TCC driver model |
| 2 | see https://docs.nvidia.com/gameworks/content/developertools/ desktop/nsight/tesla_compute_cluster.htm |
| ● | Using multiple GeForce GPUs does not yield the same performance gain. |
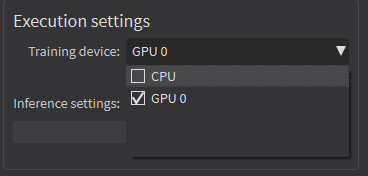
| ● | In Deep Learning Studio, to choose the training devices, check all the devices that you want to use for training. |
| ● | You can configure these execution profiles to match your needs. |
| ● | GPU processing is not possible with 32-bit applications. |
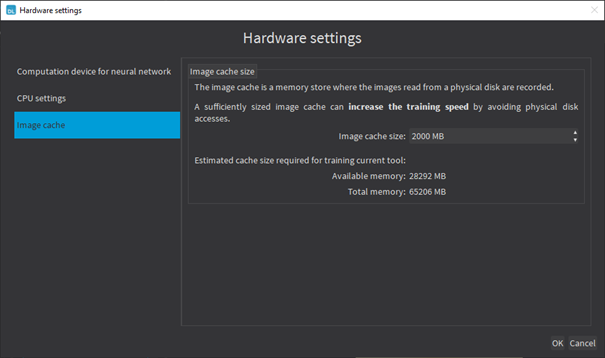
Image cache
The image cache is the part of the memory reserved for storing images during training.
| ● | The default size is 1 GB. |
| ● | The training speed is higher when the image cache is big enough to hold all the images of your dataset. |
| ● | With dataset too big to fit in the image cache, we recommend using a SSD drive to hold your images and project files as a SSD drive improves the training speed. |
To specify the cache size in bytes:
| ● | In the API, use the EDeepLearningTool::SetImageCacheSize method. |
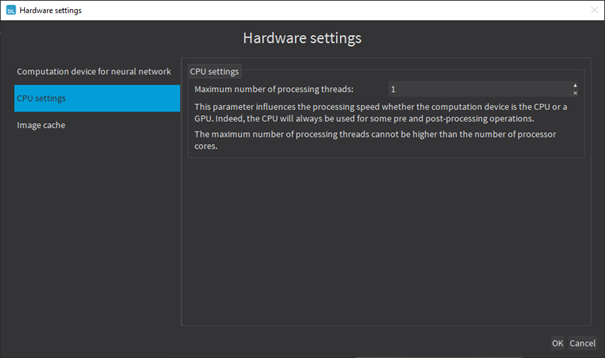
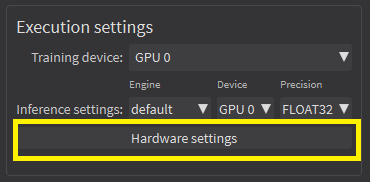
| ● | In Deep Learning Studio, click on the Hardware settings button in the Execution settings panel and select Image cache in the menu. |
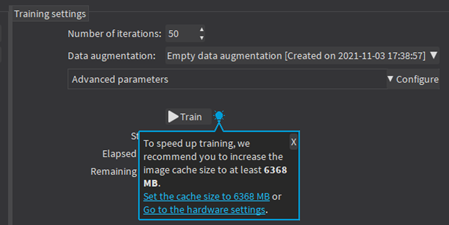
| ● | When there is enough memory to increase the image cache so that it can hold all the images in the dataset, Deep Learning Studio displays a recommendation next to the training button. |
| □ | Click on the recommendation to change the image cache size and improve the training speed. |
Multicore processing
The deep learning tools support multicore processing with the engines default and EasyDeepLeanringEngine_OpenVINO (see Multicore Processing):
| ● | In the API, use the multicore processing helper function from Open eVision (that is Easy.MaxNumberOfProcessingThreads with a value greater than 1). |
| ● | In Deep Learning Studio, click on the Configure button below the Execution profile control and select CPU Settings in the menu. |